[ C++ 스터디 ]
자료출처 : 열혈강의 C++ 프로그래밍
자료저자 : 윤성우
★ 새로운 형태의 자료형 bool ★
C++로 접어 들면서 C에는 존재하지 않았던 bool이라는 이름의 자료형이 등장하였다.
이는 false를 나타내는데 0을 , true를 나타내는데 0이 아닌 값을 이용하는 C 언어의
스타일을 탈피해서 보다 세련되게 프로그래밍하는 것을 가능하게 한다.
< 1 전통적인 방법의 true와 false >
일단 C 스타일의 예제를 먼저 살펴보자 다음 예제는 사용자로부터 값을 입력받아서
그 값이 0 이상인지 아닌지를 확인해 주는 프로그램이다. 헤더 파일도 stdio.h 를
포함해서 printf 함수와 scanf 함수를 사용하는 등 전형적인 C 스타일로 예제를
구성하였다.
/*
bool1 . cpp
C 스타일의 프로그램
*/
# include < stdio.h >
const int TRUE=1 ; // 1번
const int FALSE=0 ; // 2번
int IsPositive ( int i )
{
if ( i<0 ) // i 가 0 미만이라면
return FALSE ;
else // i 가 0 이상이라면
return TRUE ;
}
int main ( void )
{
int num ;
int result ;
printf ( " 숫자 입력: " ) ;
scanf ( " %d " , &num ) ;
result=IsPositive ( num ) ;
if ( result==TRUE )
printf ( " Positive number \n " ) ;
else
printf ( " Negative number \n " ) ;
return 0 ;
}
▶ 실행 결과
숫자 입력 : 12
Positive number
|
1번과 2번을 보자 프로그램 코드 내에서 참과 거짓을 나타내기 위해서 TRUE와
FALSE라는 이름의 상수를 정의하고 있다. 단순히 1과 0을 사용하지 않고 상수화하는
이유는 프로그램의 가독성을 위한 것이다.
< 2 bool형을 이용한 true와 false >
C++에서는 bool이라는 이름의 기본 자료형이 추가되었다. bool형 변수의 상태는 true
와 false 둘 중 하나가 될 수 있다. 여기서 말하는 true와 false는 사용자가 정의하는
상수가 아니라 기본적으로 제공이 되는 키워드에 해당이 된다.
다음은 위의 예제를 C++에서 새롭게 등장한 bool 타입의 자료형 기반으로 재구성한
것이다.
/*
bool2 . cpp
C++ 스타일의 프로그램
*/
# include < iostream >
using std : : cin ;
using std : : cout ;
using std : : endl ;
bool IoPositive ( int i ) // 1번
{
if ( i<0 ) // i 가 0 미만이라면
return false ; // 2번
else // i 가 0 이상이라면 3번
return true ;
}
int main ( void )
{
int num ;
bool result ; // 4번
cout << " 숫자 입력 : " ;
cin >>num ;
result = IsPositive ( num ) ;
if ( result == true )
printf ( " Positive number \n " ) ;
else
printf ( " Negative number \n " ) ;
return 0 ;
}
▶ 실행 결과
숫자 입력 : 100
Positive number
|
1번에 정의되어 있는 함수의 리턴 타입이나 4번에 선언되어 있는 지역 변수의 데
이터 타입이 bool 이다. 이는 2번 3번에서 리턴하고 있는 false나 true를 저장할 수
있는 데이터 타입이다.
여기서 중요한 것은 true와 false도 C++에서는 키워드라는 것이다. 즉 위의 예제
bool1 . cpp의 1번 2번에서 처럼 TRUE와 FALSE라는 이름으로 상수화시킬 필요가 없다.
이제 bool 타입의 자료형에 대해서 조금 더 보충 설명하겠다. 다음은 bool형의 데이터
가 int형의 데이터로 형 변환되었을 때 값이 얼마가 되는지를 보여 준다.
/*
bool3 . cpp
true & false
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
int main ( void )
{
int BOOL=true ; // 1번
cout << " BOOL : " <<BOOL<<endl ;
// 2번
BOOL=false ; // 3번
cout << " BOOL : " <<BOOL<<endl ;
// 4번
return 0 ;
}
▶ 실형 결과
BOOL : 1
BOOL : 0
|
1번을 보자 int형 변수 BOOL에다가 bool형 데이터 true를 삽입하고 있다. 이런 경우
true는 int형 정수 1로 묵시적 형 변환이 이뤄진다. 그래서 2번 출력결과는 1이 된다.
마찬가지로 3번에서는 int형 변수 BOOL에다가 bool형 데이터 false를 삽입하고 있다.
이런 경우 false는 int형 정수 0으로 묵시적 형 변환이 이뤄진다. 그래서 4번째 줄의
출력 결과는 0이 된다.
★ 레퍼런스 ( Reference )의 이해 ★
< 1 레퍼런스의 개념 >
필자는 어릴 적에 별다른 별명이 없었다. 평범했다는 뜻이기도 하나 한편으로는 특
징이 없다는 뜻도 되어 아쉬운 마음도 든다. 그래서 필자의 사촌 여동생을 예로 들겠
다. 이름은 유경이고 별명은 또치 ( 둘리의 친구 또치를 알고 있는가 ? )다. 정말 생
긴 것이 또치와 많이 비슷하다. 그래서 친척들이 모이면 이름보다는 주로 또치로 통
한다. 따라서 다음 두 문장은 같은 의미가 된다.
" 저는 오늘 유경에게 빵을 사줬습니다. "
" 저는 오늘 또치에게 빵을 사줬습니다. "
결론은 유경이라는 이름과 또치라는 별명은 같은 의미를 지닌다는 것이다. 레퍼런스
라는 것은 바로 이런 개념이다. 변수는 이름을 가지고 있다. 물론 함수도 이름을 가지
고 있다. 이렇게 이름을 지니고 있는 대상에게 지어주는 별명을 가리켜 레퍼런스라
한다.
레퍼런스를 선언하는 방법은 다음과 같다 ( 단 val이 int형 변수라고 가정하자 )
int &ref = val ;
위의 문장은 val 이라는 int형 변수의 이름에 ref라는 별명을 붙인 것이다. 주목해서 볼
부분은 & 연산자이다. 이 연산자는 C++에서 레퍼런스를 선언할 때에도 사용이 된다.
아마 혼동이 될 수도 있겠다. 왜냐하면 C에서는 주소 값을 얻기 위해 & 연산자를 사용
했기 때문이다. 그러나 자세히 보자 지금 & 연산자를 어디서 사용하고 있는가 ? 사용
하는 위치에 따라서 & 연산자는 주소 값을 얻는데 사용될 수도 있고 , 레퍼런스를 선
언하는데 사용될 수도 있다. 말로 더 설명하는 것보다 한번 보는 것이 훨씬 빠르겠다.
다음 코드는 이 둘을 구분 지어 준다.
int main ( void )
{
int val=10 ;
int *pVal=&val ; // 주소 값을 얻기 위해 & 연산자 사용
int *rVal=&val ; // 레퍼런스 선언을 위해 & 연산자 사용
return 0 ;
}
|
< 2 레퍼런스의 특징 >
레퍼런스가 무엇인지 개념적으로 이해를 하였는가 ? 그렇다면 레퍼런스는 어떤 특징을 지
니고 있을까 ? 아주 간단히 예제를 통해서 레퍼런스의 특징을 살펴보자.
/*
reference . cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
int main ( void )
{
int val=10 ;
int &ref=val ; // 1번
val++ ; // 2번
cout << " ref : " <<ref<<endl ; // 3번
cout << " val : " <<val<<endl ; // 4번
ref++ ; // 5번
cout << " ref : " <<ref<<endl ; // 6번
cout << " val : " <<val<<endl ; // 7번
return 0 ;
}
▶ 실행 결과
ref : 11
val : 11
ref : 12
val : 12
|
1번에서 변수 val 에다가 ref 라는 별명을 붙여주고 있다. 따라서 val 과 ref는 이제 같은
의미를 지니게 되었다.
2번에서는 val 이라는 변수의 이름으로 값을 1 증가시키고 있다. 그리고 3번 4번에서는
변수 val 이 얼마인지 레퍼런스 ref 가 얼마인지 확인차 출력하고 있다.
5번에서는 ref 라는 이름으로 값을 1 증가시키고 있다. 그리고 6번 7번에서는 변수 val이
얼마인지 , 레퍼런스 ref 가 얼마인지 확인차 출력하고 있다.
위의 예제의 출력 결과는 우리에게 다음과 같은 아주 중요한 이야기를 하고 있다.
" 레퍼런스를 가지고 하는 연산은 레퍼런스가 참조하는 변수의 이름을 가지고 하는 연산
과 같은 효과를 지닌다. "
< 3 레퍼런스에 대한 또 다른 접근 >
앞에서는 레퍼런스에 대해서 쉽게 이야기를 하였다. 이정도만 설명을 해도 레퍼런스의
본질을 파악하고 충분히 응용하는 사람들도 있겠지만 , 필자와 비슷한 사람들이라면 명
확한 무엇인가를 필요로 하기 마련이다. 다음 그림을 보자 . 변수 선언에 대한 이야기를
하고 있다.
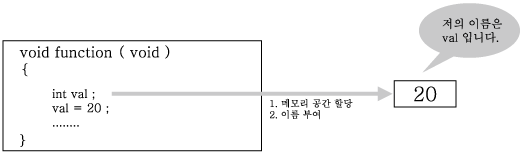
그림 2-1 : 변수 선언의 의미
위의 그림이 의미하는 바는 이미 알고 있을 것이다. 변수가 형성되는 과정과 그에 따른
결과를 이야기하는 것이다. 변수란 ? 메모리 공간에 할당된 이름을 의미한다. ( 이 정의
도 상당히 중요하다. ) 그래서 우리는 그 이름을 통해서 메모리 공간에 접근을 하게 된다.
위의 그림을 다시 보자 메모리 공간의 주소는 모르지만 val 이라는 이름을 통해서 특정
메모리의 값을 20으로 초기화하고 있지 않은가 ? 이것이 바로 메모리 공간에 이름을
붙여주는 이유이다.
C언어에서는 하나의 메모리 공간에 하나의 이름만을 부여할 수 있었다. 우의 그림처럼
말이다. C언어에서는 하나의 메모리 공간에 둘 이상의 이름을 부여하지 못했다. 그렇다
면 이제 레퍼런스가 지니고 있는 의미를 다시 한번 이야기하자. 다음 그림은 레퍼런스
를 선언하게 되면 어떠한 일이 일어나는지를 설명한다.
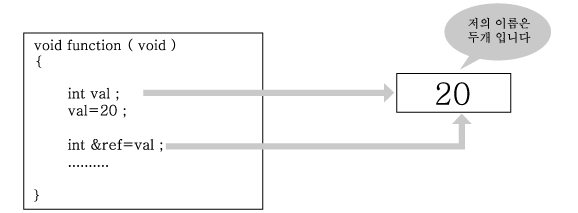
그림 2-2 레퍼런스 선언의 의미
" 레퍼런스 선언이란 이름이 존재하는 메모리 공간에 하나의 이름을 더 부여하는 행위 "
임을위 그림에서는 설명하고 있다. 그게 전부다 . 뭐 어렵게 별명을 붙여서 어떻게 된다느
니 하는말은 오히려 더 혼동될 수 있다.
그림 2-2를 다시 보자 하나의 메모리 공간에 val 이라는 이름과 ref 라는 이름이 동시에
부여되었다. 과연 이 둘 사이에는 어떠한 차이점이 있을까 ?
" 아무리 메모리 공간에 할당된 이름이라 하더라도 변수와 레퍼런스는 차이가 있겠지 "
이것이 일반적인 생각일 것이다. 더불어 레퍼런스 대해서 난해함을 느끼게 하는 요인도
된다. 필자는 여기서 과감히 말한다.
" 레퍼런스와 변수는 생성되는 방법에 있어서만 차이를 보일 뿐 만들어지고 나면 완전히
같은 것이다. "
즉 변수의 이름을 가지고 할 수 있는 일은 레퍼런스를 가지고도 할 수 있으며 , 레퍼런스
를 가지고 하지 못하는 일은 변수의 이름을 가지고도 할 수 없다는 것이다. 몇 가지 예를
통해서 이를 증명하겠다.
int function ( void )
{
int val ;
val=20 ;
int &ref=val ;
return val ;
}
|
|
int function ( void )
{
int val ;
val=20 ;
int &ref=val ;
return ref ;
}
|
|
그림 2-3 같은 의미를 지니는 코드 1
위의 그림에서 보여주는 코드를 상당히 난해하게 생각될 수 있다. 일단 왼쪽에 있는 그
림은 전혀 문제가 없다. 리턴 타입이 int형이고 리턴되는 대상도 int형 변수이기 때문이다.
오른쪽 그림은 어떤가 ? 조금 이상하지 않은가 ? 리턴되는 대상이 레퍼런스인데 리턴
타입이 int 형이니 말이다.
앞에서 뭐라 했는가 ? 레퍼런스도 일단 만들어지면 변수와 100% 같은 의미를 지닌다고
하지 않았는가 ? 즉 ref도 만들어지는 과정이 일반 변수와 달라서 레퍼런스라고 하는
것이지 int형 변수와 차이가 없다. 즉 위의 그림에서 보여 주는 두 개의 코드는 100%
같은 의미를 지니며 문제도 없는 코드들이다.
한가지 예를 더 보자 . 레퍼런스를 선언하면 하나의 메모리 공간에 셋 이상의 이름을
부여하는 것도 문제될 것이 없다.
void function ( void )
{
int val ;
val=20 ;
int &ref1=val ;
int &ref2=ref1 ;
}
|
|
void function ( void )
{
int val ;
val=20 ;
int &ref1=val ;
int &ref2=val ;
}
|
|
그림 2-4 같은 의미를 지니는 코드 2
위의 그림에서 제시하는 두 가지 코드를 보면 하나의 변수 val에 두 개의 이름 ref1과
ref2를 더 부여하려고 하고 있음을 알 수 있다. 차이가 나는 부분은 ref2라는 이름의
레퍼런스를 선언하는 방식이다. 왼쪽에 있는 코드는 레퍼런스 ref1을 이용해서 ref2를
선언하고 있으며 , 오른쪽에 있는 코드는 변수 val을 이용해서 ref2를 선언하고 있다.
이 둘의 차이점은 무엇이겠는가 ?
차이점은 없다.
< 4 레퍼런스의 제약 >
레퍼런스와 변수의 차이점은 만들어지는 과정에 있다고 하였다. 변수는 새로운
메모리 공간에 이름을 부여한다는 특징을 지니지만 , 레퍼런스는 이미 이름을 지니고
있는 메모리 공간에 하나의 이름을 더 부여한다는 특징을 지닌다. 따라서 다음과 같은
코드는 잘못된 것이다.
int main ( void )
{
int &ref1 ; // 초기화되지 않았으므로 ERROR ! // 1번
int $ref2=10 ; // 상수가 올 수 없으므로 ERROR ! // 2번
int val=10 ;
ref1=val ;
............
}
|
우선 1번의 ref1의 선언은 초기화되지 않았으므로 오류다. 레퍼런스는 선언과 동시에
반드시 초기화되어야 하기 때문이다. 그렇다고 해도 2번과 같은 형식의 초기화는 문제가
있다. 레퍼런스는 이름을 지니는 변수에 이름을 하나 더하기 위한 것이다. 그런데
2번에서는 레퍼런스를 이름도 지니지 않는 상수로 초기화하려 하고 있다. 따라서 이는
문제다. 그 이외에도 레퍼런스를 사용함에 있어서 주의를 해야 할 사항들이 몇 가지 있는데
이는 잠시 후에 살펴보기로 하자.
★ 레퍼런스와 함수 ★
< 1 포인터를 이용한 Call-By-Reference >
우리가 여기서 언급할 내용은 Call-By-Reference 다. 다음 예제는 포인터를 이용한
Call-By-Reference 방식의 swap 함수 ( 두 개의 값을 바꾸는 기능의 함수 ) 를 보여 준
다. 예제의 중요성은 이루 말할 수 없다. 혹시 잘 이해가 되지 않는다면 C 관련 서적을
다시 한번 참고하기 바란다.
/*
swap1 . cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
void swap ( int *a , int *b )
{
int temp=*a ;
*a=*b ;
*b=temp ;
}
int main ( void )
{
int val1=10 ;
int val2=20 ;
cout << " val1 : " << val1 << '
' ;
cout << " val2 : " << val2 << endl ;
swap ( &val1 , &val2 ) ;
cout << " val1 : " << val1 << '
' ;
cout << " val2 : " << val2 << endl ;
return 0 ;
}
▶ 실행 결과
val1 : 10 val2 : 20
val1 : 20
val2 : 10
|
이 예제를 통해서 Call-By-Reference의 장점을 이야기해 보자 일단 함수 호출 시 전달
되는 포인터를 이용해서 포인터가 가리키는 메모리 공간에 직접 접근이 가능하다는데
있다. 그래서 이 예제에서도 main 함수 내에 선언되어 있는 두 변수의 값을 swap 함수 내
에서 직접 변경하는 것이 가능하다는 것을 보여 주고 있다.
그것이 장점이라면 단점은 무엇이 있을까 ? 위의 예제에서 swap 함수를 다음과 같이 변
경해서 실행해 보자 그리고 실행 시 어떠한 문제점이 발생하는지에 대해서도 확인하기 바
란다.
void swap ( int *a , int *b )
{
int temp=*a ;
a++ ;
// 잘못 들어간 코드 // 1번
*a=*b ;
*b=temp ;
}
|
위 함수의 1번은 잘못 들어간 코드라고 생각하자. 이유야 다양하지 않겠는가 ? 프로그래머
가 잘못 구현했을 수도 있고 , 다른 코드를 일부 복사 ( Copy & Paste ) 하다 들어간 것일
수도 있다. 다음 그림은 위의 swap 함수를 가지고 예제 swap1 . cpp를 실행하는 경우에
보게 되는 오류 메시지이다. 아마 C 언어에서 포인터와 배열을 공부하면서 종종 봤을 것
이다.
그래서 포인터를 이용한 Call-By-Reference의 단점은 무엇이란 말인가 ? 포인터는 포인터
연산이 가능하기 때문에 잘못된 메모리 접근을 할 가능성이 높다는 것이다. 경우에 따라서
는 포인터 연산이 가능하다는 것이 단점으로 적용한다. 위의 예제를 보라. swap 함수에서
포인터 연산을 할 필요가 있는가 ?
< 2 레퍼런스를 이용한 Call-By-Reference >
장점은 취하고 단점은 버리면 된다. 즉 함수 내에서 외부에 존재하는 변수에 접근하는 것
은 허용을 하되, 포인터 연산은 못하게 하자는 뜻이다. 어떠한 방법이 있는가 ? 그렇다 !
레퍼런스를 사용하는 것이다. 다음은 위의 예제 swap1 . cpp를 레퍼런스를 이용해서
재구현한 것이다.
/*
swap2 . cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
void swap ( int &a , int &b ) // 1번
{
int temp=a ;
a=b ;
b=temp ;
}
int main ( void )
{
int val1=10 ;
int val2=20 ;
cout << " val1 : " << val1 << '
' ;
cout << " val2 : " << val2 << endl ;
swap ( val1 , val2 ) ; // 2번
cout << " val1 : " << val1 << ' ' ;
cout << " val2 : " << val2 << endl ;
return 0 ;
}
▶ 실행 결과
val1 : 10 val2 : 20
val1 : 20 val2 : 10
|
2번에서 val1과 val2를 인자로 전달하면서 1번에서 정의되어 있는 swap 함수를 호출하고
있다. 그런데 swap 함수는 전달되는 인자를 레퍼런스로 받고 있다. 이 상황을 그림으로
설명하면 다음과 같다.
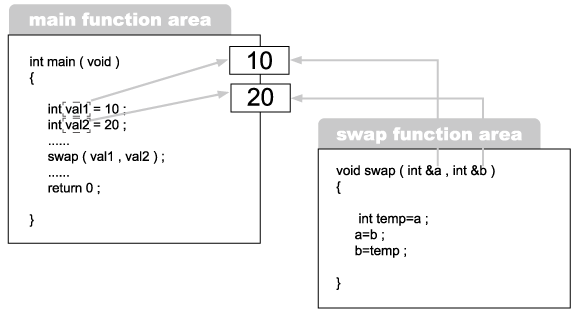
그림 2-6 레퍼런스를 이용한 swap 함수의 구현
일단 그림의 왼쪽 부분을 보자 main 함수 내에서 두 개의 메모리 공간을 할당하고 각각
10과 20으로 초기화한 다음에 각각 val1 과 val2라는 이름을 부여한 상황을 설명하고 있
는 것이다.
그 다음 swap 함수를 호출하면서 val1 과 val2를 인자로 전달하고 있다. 그런데 swap 함
수는 절달되는 인자를 레퍼런스로 받고 있다. 즉 main 함수 내에서 선언한 변수 val1 과
val2라는 이름이 붙어 있는 메모리 공간에 a 와 b라는 이름이 하나씩 더 붙게 된 것이다.
위 그림의 오른쪽 부분은 이것을 이야기하고 있다.
여기서 중요한 핵심 포인터는 레퍼런스 a 와 b는 swap 함수의 매개 변수로 선언된 것
이므로 swap 함수 내에서 참조 가능한 이름이라는 것이다. 결국 swap 함수 내에서는
a와 b라는 이름으로 main 함수 내에 선언된 변수 val1 과 val2에 직접 접근이 가능하
게 된 것이다.
이제 레퍼런스가 가지고 있는 장점이 무엇인지 살짝 감이 왔을 것이다. 게다가 위의 예
제를 보면 여러분이 그리도 어려워하는 포인터가 눈에 보이질 않는다. 이렇듯 레퍼런스
는 특정 상황 하에서 포인터를 대체할 수 있다는 특징을 지니고 있다.
그러나 단점도 있다. 위의 예제 2번을 보자 이것만 봐서는 도대체 이 swap 함수가
Call-By-Value인지 Call-By-Reference인지 감을 잡지 못한다. " 위에 swap 함수의
정의가 있으니까 그것을 참조하면 되지 " 라고 생각할지도 모르겠다. 물론 틀린
생각은 하니다. 그러나 프로그램의 길이가 길어진다면 , 그리고 확인해야 할 함수가
상당히 많다면 상황은 달라질 수 있다.
★ 레퍼런스를 이용한 성능의 향상 ★
앞에서 레퍼런스를 이용한 Call-By-Reference에 대한 내용을 이야기하였다. 포인터를
이용한 Call-By-Reference보다 좋은 점도 이야기하였고 , 나쁜 점도 이야기하였다.
이번에 할 이야기는 Call-By-Value에 대한 내용이다.
< 1 부담스러운 Call-By-Value >
레퍼런스는 적절한 시점에 사용한다면 성능 향상에 도움이 되기도 한다. 다음 예제를 보
자 개인 정보를 입력 및 출력하는 예제이다.
/*
reffunc . cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
using std : : cin ;
struct _Person // 1번
{
int age ; // 나이
char name[ 20 ] ; // 이름
char personalID[ 20 ] ; // 주민등록 번호
} ;
typedef struct _Person Person ;
void ShowData ( Person p ) // 2번
{
cout << " ******** 개인 정보 출력 ******** " << endl ;
cout << " 이 름 : " << p.name << endl ;
cout << " 주민번호 : " << p.personalID << endl ;
ocut << " 나 이 : " << p.age << endl ;
}
int main ( void )
{
Person man ; // 3번
cout << " 이 름 : " ;
cin >> man.name ; // 4번
cout << " 나 이 : " ;
cin >> man.age ; // 5번
cout << " 주민번호 : " ;
cin >> man.personalID ; // 6번
ShowData ( man ) ; // 7번
return 0 ;
}
▶ 실행 결과
이 름 : YoonSungWoo
나 이 : 18
주민번호 : 860208-20117124
******** 개인 정보 출력 ********
이 름 : YoonSungWoo
주민번호 : 860208-20117124
나 이 : 18
|
1번에는 개인의 기본 정보 ( 이름 , 주민등록 번호 , 나이 )를 저장할 수 있는 구조체를
정의 하고 있다.
2번에서는 구조체 변수의 정보를 출력하는 함수가 정의되어 있다. 전달되는 인자를 어떻
게 받겠다고 선언되어 있는 주의 깊게 보기 바란다.
3번에서 구조체 변수를 하나 선언한 다음 4번 5번 6번에서 각각 이름 , 나이 주민등록
번호를 입력받고 있다.
7번에서는 입력받은 데이터를 출력하기 위해서 구조체 변수 man을 인자로 전달하고 있
다. 그런데 전달하는 방식이 Call-By-Value다. 따라서 변수 man을 매개 변수 p에 복사
하게 된다. 이 과정에서 복사되는 바이트의 수는 44바이트 ( 4+20+20 )에 이른다.
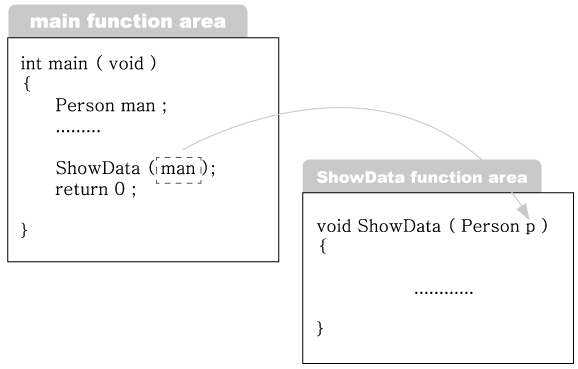
그림 2-7 : 구조체 변수를 이용한 Call-By-Value
Call-By-Value의 기본 방식은 값의 복사이다. 그래서 위와 같은 예제의 경우 ( 인자로
전달하는 변수의 크기가 만만치 않은 경우 ) 에는 함수의 호출이 부담스러울 수밖에
없다.
< 2 부담스러운 Call-By-Value를 대신하는 Call-By-Reference >
위에서 제시한 예제 reffunc.cpp에 정의되어 있는 함수 ShowData의 경우 , 함수 호
출 시 44바이트나 되는 크기의 복사 때문에 함수 호출 자체가 부담이 된다고 이야기하
였다. 이러한 부담을 레퍼런스를 이용해서 해결하고자 한다. 다음은 위에서 정의한 함
수 ShowData를 레퍼런스를 이용한 형태로 변경한 것이다.
void ShowData ( Person &p )
{
cout << " ******** 개인 정보 출력 ******** " << endl ;
cout << " 이 름 : " << p.name << endl ;
cout << " 주민번호 : " << p.personalID << endl ;
ocut << " 나 이 : " << p.age << endl ;
}
|
위의 함수는 전달되는 인자를 레퍼런스 형태로 받고 있다. 직관적으로 생각해 봐도
해가 가는 부분이다. 레퍼런스의 형태로 받게 되면 , 이름만 하나 더 추가하는 것이므
로 44바이트나 되는 크기의 복사는 발생하지 않는다. 따라서 성능은 향상될 수밖에
없다.
이제 모든 문제는 해결이 된 듯하다. 그러나 한가지 더 집고 넘어가야 할 부분이 있다.
분명히 함수 ShowData는 인자로 전달된 구조체 변수의 데이터를 출력하는 함수
이지 , 데이터 자체를 조작하기 위한 함수는 아니다. 그럼에도 불구하고 우리는 ( 사
람이기에 ) 데이터를 변경하는 우( 愚 )를 범 할 수도 있다. 이런 경우 레퍼런스의
특성 때문에 원본 데이터 ( main 함수 내에 선언되어 있는 구조체 변수 man )가
변경되는 문제가 발생할 수도 있으며 , 이보다 더 큰 문제는 이러한 형태의 오류는
컴파일-타임 ( 컴파일하는 동안 )에도 , 그리고 런-타임 ( 실행하는 동안 )에도 경고
메시지 한번 받아보기 어렵다는 것이다. 즉 디버깅 자체가 상당히 까다로워질 수
밖에 없다. 그렇다면 이 문제를 어떻게 해결하는 것이 좋겠는가 ?
가장 좋은 방법은 데이터를 변경하는 우를 범하는 경우 , 컴파일-타임에 에러 메시지
를 띄우도록 함수를 구현하는 것이다.
void ShowData ( const Person &p )
{
cout << " ******** 개인 정보 출력 ******** " << endl ;
cout << " 이 름 : " << p.name << endl ;
cout << " 주민번호 : " << p.personalID << endl ;
ocut << " 나 이 : " << p.age << endl ;
}
|
위의 함수는 우리가 얻고자 하는 최종 결과에 해당된다. 레퍼런스의 선언 앞에 키워드
const를 붙여주고 있다. 즉 레퍼런스 p 자체를 상수화하겠다는 것이다. 이것이 무슨
뜻이냐 하면 " 레퍼런스 p를 통한 데이터의 조작을 허용하지 않겠다. " 라는 뜻이다.
만약에 잘못해서 p를 이용해서 데이터를 조작하는 코드가 삽입되는 경우 컴파일러는
에러메시지를 발생시켜 줄 것이다. 한번 확인해 보기 바란다.
★ 레퍼런스를 리턴하는 함수의 정의 ★
앞에서는 전달되는 인자를 레퍼런스로 받는 경우에 대해서 언급하였다. 이번에는 함
수 내에서 값을 반환할 때 레퍼런스로 반환하는 경우에 대해서 언급을 하겠다. 의
외로 많이 혼란스러워 하는 부분이다. 따라서 간단한 예제를 통해서 개념적인 이해
를 돕도록 하겠다.
< 1 레퍼런스를 리턴하는 적절한 형태의 함수와 그 의미 >
설명이 들어가기에 앞서서 다음 예제를 보고 어떻게 돌아가는지 나름대로 그림을 그
려보기 바란다.
/*
ref_return.cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
int& increment ( int &val )
{
val++ ; // 1번
return val ; // 2번
}
int main ( void )
{
int n=10 ; // 3번
int &ref=increment ( n ) ; // 4번
cout << " n : " << n << endl ;
cout << " ref : << ref << endl ;
return 0 ;
}
▶ 실행 결과
n : 11
ref : 11
|
3번에서 n 이라는 이름의 변수를 선언하고 10으로 초기화하였다.
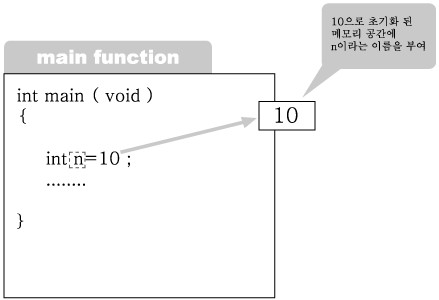
그림 2-8 : n이라는 이름의 변수 선언
4번에서는 n을 인자로 전달하면서 increment 함수를 호출하고 있다. 그런데 이 함수
는 전달인자를 레퍼런스 val로 받고 있다. 따라서 n이라는 이름이 붙어 있는 메모리
공간에 val이라는 이름이 하나 더 붙게 되었다.
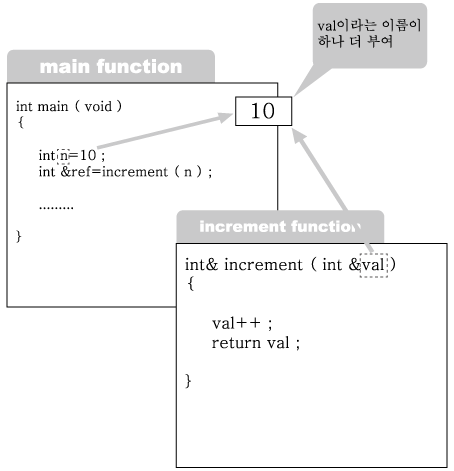
그림 2-9 : 레퍼런스 val에 의한 참조
1번을 보면 increment 함수 내에서 val이라는 이름이 붙어 있는 메모리 공간의 값을
하나 증가시킨다. 따라서 변수 n의 값은 11이 된다. 그리고 나서 2번에서 val을 레퍼
런스 타입으로 리턴하고 있으며 , 4번에서는 이를 ref라는 이름의 레퍼런스로 받고
있다. 따라서 상황은 다음 그림과 같이 전개될 것이다.
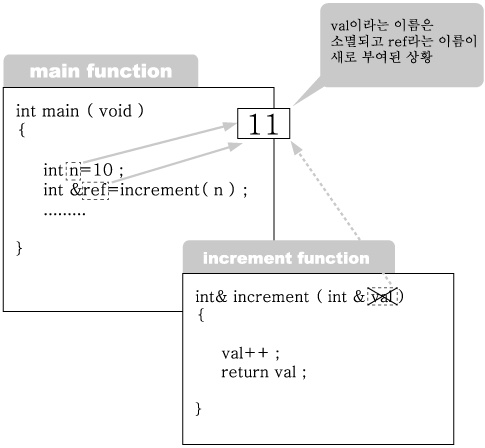
그림 2-10 : 레퍼런스 val에 의한 리턴
한가지 주의할 것은 매개 변수로 선언된 레퍼런스 val은 지역 변수와 마찬가지로 함
수의 호출이 완료되면 사라져버리는 것이다. 그러나 이름만 사라질 뿐이다. val이라는
이름이 붙어 있는 메모리 공간까지 사라지는 것은 아니다.
< 2 레퍼런스를 리턴하는 잘못된 형태의 함수 >
레퍼런스를 리턴할 때는 주의해야 할 사항이 한가지 있는데 , 그것은 다음과 같다.
" 지역 변수는 레퍼런스로 리턴할 수 없다. "
다음 예제를 보고 문제점을 직접 지적해 보자 앞의 예제와 마찬가지로 개념적 이해를
위해서 예제는 가급적 간단히 만들어 놓았다.
/*
ref_error.cpp
*/
# include < iostream >
using std : : cout ;
using std : : endl ;
int& function ( void )
{
int val=10 ;
return val ; // 1번
}
int main ( void )
{
int &ref=function( ) ; // 2번
cout << ref << endl ; // 3번
return 0 ;
}
|
2번에서 function 함수를 호출하고 있고, 함수 내에서는 val이라는 이름의 변수를 선언
하고 있다.
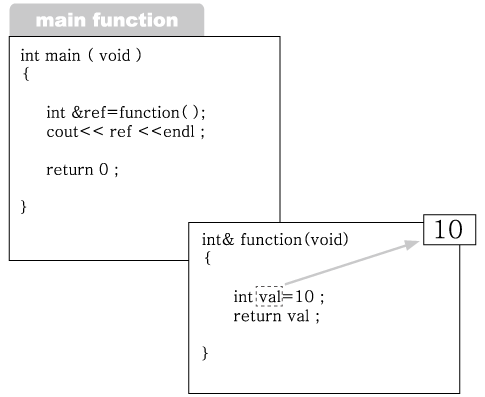
그림 2-11 : 지역 변수 val의 선언
1번에서 변수 val을 레퍼런스로 리턴하고 있으며 , 이를 main 함수에서는 ref라는 이름으
로 받아 주고 있다.
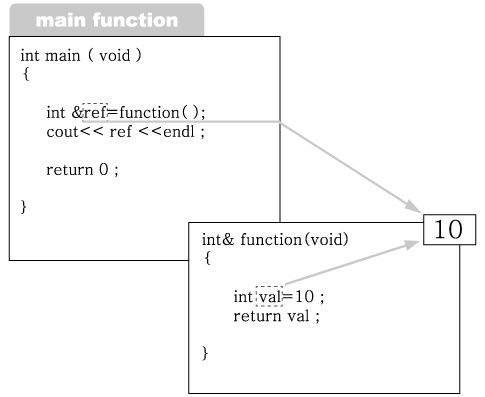
그림 2-12: 레퍼런스 형태로 val을 리턴 1
어떤가 , 그림 2-12는 적절한 그림이라고 생각이 드는가? 아니다 ! 틀린 그림이다. 왜냐하
면 함수가 종료되면 function 함수의 지역 변수 val은 사라져버리기 때문이다. 그렇다면
그림을 정확히 그려 보자.
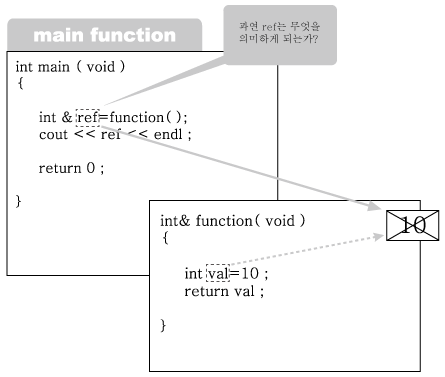
그림 2-13: 레퍼런스 형태로 val을 리턴 2
3번에서는 ref를 출력하고 있다. 문제는 ref라는 이름이 붙어 있던 메모리 공간이 사라
져버렸다는 것이다. 그래서 출력 결과가 얼마가 나올지 아무도 예상하지 못한다. 혹 !
제대로 출력이 되었다 하더라도 이는 보장받을 수 없는 값에 해당된다.
결론이다. 위 예제에서 언급한 문제를 만들지 않으려면 , 지역 변수를 레퍼런스로 리턴하
는 일은 없어야 한다.
★ new & delete ★
< 1 new오 delete 연산자의 기본적 기능 >
메모리를 동적으로 할당 및 소멸하기 위해서 malloc과 free함수를 써 본 경험이 있을
것이다. C++에서는 new와 delete 키워드가 이 두 함수를 대신한다.
2-1을 통해서 malloc 함수와 free 함수의 기능 및 메모리 동적 할당의 필요성은 이해하
였다고 가정하고 여기서는 new와 delete 사용법에 대해서만 언급하겠다.
다음 예제에서는 malloc과 free 함수를 사용해서 동적으로 메모리 공간을 할당하고 있다.
배열의 크기를 사용자로부터 입력받는 관계로 malloc과 free 함수의 호출이 절대적이다.
/*
malloc_free.cpp
*/
# include < iostream >
using std : : cin ;
using std : : cout ;
using std : : endl ;
int main ( void )
{
int size ;
cout << " 할당하고자 하는 배열의 크기 : " ;
cin >> size ;
int* arr=( int* )malloc( sizeof ( int )* size ) ; // 배열의 동적 할당 // 1번
for ( int i=0 ; i<size ; i++ )
arr[ i ]=i+10 ;
for ( int j=0 ; j<size ; j++ )
cout << " arr[ " <<j<< " ]=
" << arr[ j ] << endl ;
free ( arr ) ; // 할당된 메모리 소멸 // 2번
return 0 ;
}
▶ 실행 결과
할당하고자 하는 배열의 크기 : 5
arr[ 0 ]= 10
arr[ 1 ]= 11
arr[ 2 ]= 12
arr[ 3 ]= 13
arr[ 4 ]= 14
|
위 예제에서는 malloc과 free 함수를 호출하고 있다. 만약에 컴파일 에러가 발생한다면
stdlib.h 헤더 파일을 포함 ( # include < stdlib.h > )해 주가 바란다.
1번에서는 malloc 함수를 호출하고 있다. 이 함수는 인자로 전달된 크기만큼 단순히 메
모리 공간을 할당만 하기 때문에 byte 단위로 할당하고자 하는 메모리 공간의 크기를
전달해야하고 , 또 void 포인터형으로 반환되는 포인터를 적절히 형 변환해서 사용해야
한다.
2번에서는 free 함수를 통해서 할당받은 메모리 공간을 반환하고 있다.
위 예제는 C++의 키워드 new와 delete를 사용하면 한결 간단해진다. 다음은 new
키워드의 사용 방법을 설명하고 있다.
int main ( void )
{
// int 형 데이터 1개 저장을 위한 메모리 할당
int * val = new int ; // 1번
// 길이가 size인 int형 배열을 위한 메모리 할당
int * arr = new int [ size ] ; // 2번
}
|
C++에서 new는 연산자이다. 피연산자는 오른쪽에 오게 되는데, 할당하고자 하는 데이터의
형태가 오게 된다. 1번줄을 보자 대입 연산자의 오른쪽에 다음과 같은 문장이 있다.
new int
이것은 int형 데이터 하나를 저장할 수 있는 메모리 공간을 동적 할당하라는 선언이다. 따
라서 힙영역에 4byte 메모리 공간이 할당될 것이고 , 할당된 메모리 공간의 주소 값 반환
이 이루어진다.
이 부분에 있어서는 malloc 함수와 비슷하다는 생각이 드는가? 큰 차이가 있다. malloc 함
수는 주소 값을 void 포인터 ( void* )형으로 반환하기 때문에 형 변환을 해야만 했지
만 여기서는 그럴 필요가 없다.
new 연산자는 용도에 맞게 포인터를 반환하기 때문이다. 즉 int형 데이터를 저장하기
위한 메모리 공간을 할당하게 되면 int형 포인터로 주소 값이 반환된다. 따라서 다음과 같
은 문장을 구성하게 된 것이다.
int * arr = new int ;
2번에서는 배열을 할당하는 방법을 보여주고 있다. 역시 어려울 것 없다. 할당하고자
하는 데이터의 형태를 선언만 해주면 된다. 이 문장은 길이가 size인 int형 배열 선언
을 요구하는 것이다. int형 배열 할당을 요구하고 있으므로 이번에도 역시 int형 포인
터로 주소 값이 반환될 것이다.
int * arr = new int[ size ] ;
이번에는 할당된 메모리 공간을 반환하는 방법에 대해서 알아보자.
int main ( void )
{
// int 형 데이터 저장을 위한 메모리 할당
int * val = new int ;
// int형 배열을 위한 메모리 할당
int * arr = new int [ size ] ;
.............
// val이 가리키는 메모리 반환
delete val ; // 1번
// arr이 가리키는 배열 반환
delete [ ] arr ; // 2번
............
}
|
new 연산자에 의해 할당된 메모리 공간을 해제할 때는 delete 연산자를 사용하면 된
다. 1번을 보자 val이라는 포인터가 가리키는 메모리 공간을 반환하라는 의미이다.
여기서는 val이 int형 포인터이므로 val의 주소를 시작으로 4바이트가 반환될 것이다.
한가지 주의할 것은 할당된 메모리 공간이 배열일 경우이다. 2번을 보자 포인터 앞에 인덱
스 기호 ( [ ] )가 있다.
delete [ ] arr ;
이것은 arr 포인터가 가리키는 것이 배열이므로 배열의 반환을 요구하는 것이다. 기억하자 !
배열을 반환할 경우에는 인덱스 기호를 붙여줘야 한다. 2차원 배열이건 , 3차원 배열이건
배열을 해제 할 때는 2번과 같이 요구하면 된다.
참고 다음 세 문장은 같은 의미를 지닌다.
delete[ ] arr ;
delete [ ]arr ;
delete [ ] arr ;
다음은 앞에서 본 malloc_free.cpp 를 new와 delete를 사용해서 재구현한 예제이다.
/*
new_delete.cpp
*/
# include < iostream >
using std : : cin ;
using std : : cout ;
using std : : endl ;
int main ( void )
{
int size ;
cout << " 할당하고자 하는 배열의 크기 : " ;
cin >> size ;
int* arr=new int [ size ] ; // 배열의 동적 할당
for ( int i=0 ; i<size ; i++ )
arr[ i ]=i+10 ;
for ( int j=0 ; j<size ; j++ )
cout << " arr [ " << j << " ]= "<< arr[ j ] <<endl ;
delete [ ] arr ; // 할당된 메모리 소멸
return 0 ;
}
▶ 실행 결과
할당하고자 하는 배열의 크기 : 5
arr[ 0 ]= 10
arr[ 1 ]= 11
arr[ 2 ]= 12
arr[ 3 ]= 13
arr[ 4 ]= 14
|
결론이다. ! new 연산자를 사용하면 malloc과 달리 , 할당하고자 하는 메모리 공간의
크기를 계산해야 할 필요도 없으며 , 적절한 형태로 포인터를 형 변환해 줄 필요도
없다.
< 2 NULL 포인터를 리턴하는 new 연산자 >
new 연산자는 메모리를 동적으로 할당하는 연산자임을 알게 되었다. 그런데 메모리 공간
이 여의치 않다면 ( 메모리를 할당만 하고 , 적절히 소멸해 주지 않을 경우에 발생 )
new 연산자에 의한 메모리 할당이 실패로 돌아갈 수도 있는 일이다. 이러한 경우 new
연산자는 NULL 포인터를 리턴한다.
NULL 포인터란 정우 0을 의미하는 것이다. 매크로로 정의되어 있는 상수 NULL을 사용
해도 되고, 0을 직접 사용할 수도 있다. 둘 다 NULL 포인터를 의미한다.
앞에서 살펴본 예제 new_delete.cpp의 main 함수는 다음과 같이 변경되어야 더 안정
적인 프로그램이 된다.
/*
NULL_new.cpp
*/
# include < iostream >
using std : : cin ;
using std : : cout ;
using std : : endl ;
int main ( void )
{
int size ;
cout << " 할당하고자 하는 배열의 크기 : " ;
cin >> size ;
int* arr=new int [ size ] ; // 배열의 동적 할당 // 1번
if ( arr=NULL ) // 동적 할당 검사 // 2번
{
cout << " 메모리 할당 실패 " << endl ;
return -1 ; // 프로그램 종료
}
for ( int i=0 ; i<size ; i++ )
arr[ i ]=i+10 ;
for ( int j=0 ; j<size ; j++ )
cout<< " arr[ " << j << " ]= " << arr[ j ] <<endl ;
delete [ ] arr ; // 할당된 메모리 소멸
return 0 ;
}
|
이전 예제와 차이가 나는 부분은 2번이다. 1번에서 메모리 할당을 하고 난 다음에 할
당이 제대로 이뤄졌는지를 검사하고 있다.
일반적으로 프로그램머들은 본인의 메모리 관리 능력과 운영체제의 메모리 관리 능력
을 믿는 편이다. 따라서 위의 예제 2번 같은 메모리 검사 코드는 필요 없다고 생각한다.
오히려 if 문과 같은 비교문을 통해서 성능만 저하시킬 뿐이라고 생각을 한다.
이는 충분히 일리가 있는 말이다 . 그래서 프로그램을 테스트하는 과정에서는 위와 같
은 오류 검사코드를 넣었다가도, 실제 서비스를 하기 위한 최종 버전을 컴파일할 때
에는 오류 검사 코드를 포함시키지 않는 방법을 선택하기도 한다.
매크로를 이용하면 이러한 일들을 일괄적으로 쉽게 처리할 수 있다. 다음 예제를 통해
서 힌트를 얻기 바란다. ( 참고로 다음 예제는 앞으로 나갈 진도와는 관계가 없는 부
분이며 , C++ 보다는 C 언어에 관련이 더 깊은 내용이다 ).
/*
Debug_new.cpp
*/
# include < iostream >
# define DEBUG 1 // 테스트 버전 컴파일 시 // 1번
// # define DEBUG 0 // 최종 서비스 버전 컴파일 시 // 2번
using std : : cin ;
using std : : cout ;
using std : : endl ;
int main ( void )
{
int size ;
cout << " 할당하고자 하는 배열의 크기 : " ;
cin >> size ;
int* arr=new int[ size ] ; // 배열의 동적 할당 // 3번
# if DEBUG==1 // 4번
cout << " 디버그 모드 입니다. " << endl ; // 5번
if ( arr==NULL )
{
cout << " 메모리 할당 실패 " <<endl ;
return -1 ; // 프로그램 종료 // 6번
}
#endif // 7번
for ( int i=0 ; i<size ; i++ )
arr[ i ]=i+10 ;
for ( int j=0 ; j<size ; j++ )
cout << " arr[ " << j << " ]= " << arr[ j ] <<endl ;
delete [ ] arr ; // 할당된 메모리 소멸
return 0 ;
}
|
우선 4번부터 7번까지 보자 3번에 의해서 메모리가 제대로 할당이 이뤄졌는지를 검
사하는 코드가 #if ~ #endif 문에 의해서 조건부 컴파일을 구성하고 있다. 만약에
#if ~ #endif가 어떤 의미를 지니는지 잘 모른다면 , C 언어 관련 서적을 참고하기 바란
다.
이번에는 1번 2번을 보자 DEBUG라는 매크로 상수 값을 설정하고 있다. 2번을 주석
처리해서 이 값이 1이 되면 , 5번부터 6번까지 포함되어 컴파일될 것이다.
2번의 주석을 해제하고 1번을 주석 처리한다면 DEBUG는 0이 되므로 5번부터 6번까지
컴파일 대상에서 제외될 것이다.