
[ 그림 11-1 ] Member 구조체의 기억 형태
자료출처 : 핵심 길잡이 C 프로그래밍언어
도서출판 : 성안당
구조체 ( Structure )는 데이터 추상화의 중요한 기법 중의 하나로, 하나 이상의 데이
터 타입을 가진 변수들의 모임을 의미한다.
배열은 데이터형의 같고 동일한 성격을 가진 데이터들의 처리에 사용된다. 그러나 ,
일반적으로 데이터는 여러 가지 서로 다른 성격을 지닌 요소들의 집합으로 구성되어
있으며 , 또한 이들 요소들도 각각 다른 데이터형을 가질 수 있다. 예를 들면 , 사원의 인
적 사항은 사원 번호 , 성명 , 성별 , 나이 , 주소 , 전화 번호 등으로 구성될 수 있으며 , 책
( book )인 경우에는 책제목 , 저자 , 출판사 , 출판년도 , 가격 등으로 나타낼 수 있다.
구조체는 이와 같이 성격은 다르지만 서로 관련이 있는 데이터들을 하나로 묶어서
나타낼 수 있는 데이터의 한 가지 형태 ( type )라고 할 수 있다.
구조체를 정의하는 일반 형식은 다음과 같다.
| 형 식 |
|
예를 들어 , 신입 사원의 인적 사항을 사원 번호 , 성명 , 성별 , 나이 주소 전화 번호로
나타낸다고 할 때 , 다음과 같이 구조체로 정의할 수 있다.
struct Member
{
int number ; // 사원번호
char name[ 20 ] ; // 성명
char sex ; // 성별
int age ; // 나이
char address[ 30 ] ; // 주소
char tel[ 12 ] ; // 전화 번호
}
여기서, struct는 예약어이며, Member는 구조체명을 나타낸다. 구조체명은 변수가
아니라 구조( structure )의 형태( template )를 나타내는 식별자로서 구조체를 변수를 선언
할 때 사용된다. 그리고 number , name , sex , age 등과 같이 구조체를 구성하는 요소
들을 맴버( member ) 또는 항목( item )이라 한다. 구조체 맴버는 단순 변수나 배열일
수도 있고 , 포인터 변수 , 구조체 변수 및 구조체 포인터 변수일 수도 있다.
구조체의 정의는 실제 기억 장소를 확보하는 것이 아니라 데이터의 구성 형태를 정
의하는 것으로서, 정의된 구조체로 변수를 선언하면 실제 기억 장소가 확보된다. [ 그림
11 -1 ]은 사원의 인적 사항에 대한 구조체형의 기억 형태를 그림으로 나타낸 것이다.
[ 그림 11-1 ] Member 구조체의 기억 형태
구조체 변수는 미리 정의된 구조체를 데이터형으로 갖는 변수를 의미한다. 구조체
변수를 선언하는 형식은 다음과 같다.
| 형 식 |
| [ 기억 클래스 ] struct 구조체명 구조체변수1 [ , 구조체변수2 , .... , 구조체변수n ] ; |
| 형 식1 ( 구조체와 구조체 변수를 동시에 선언할 경우 ) |
|
| 형 식2 ( 구조체명을 생략한 경우 ) |
|
예를 들어 , 앞에서 정의한 구조체 Member를 사용하여 다음과 같이 구조체 변수를
선언할 수 있다.
struct Member insu , younghi ;
여기서 insu와 younghi는 Member라는 구조체형을 갖는 구조체 변수이다. 또한 구
조체 정의와 구조체 변수의 선언을 동시에 할 수도 있는데 , 예를 들면 다음과 같다.
struct Member // 구조체 Member 정의
{
int number ;
char name[ 20 ] ;
char sex ;
int age ;
char address[ 30 ] ;
char tel[ 12 ] ;
} insu , younghi ; // 구조체 변수 insu , yunghi 선언
또는
struct // 구조체명을 생략한 경우
{
int number ;
char name[ 20 ] ;
char sex ;
int age ;
char address[ 30 ] ;
char tel[ 12 ] ;
} insu , younghi ; // 구조체 변수 insu , younghi 선언
구조체 변수의 멤버를 참조하고자 할 경우에는 구조체 멤버 연산자( structure mem-
ber operator )인 도트 연산자( dot operator : . )로 나타내야 한다. 도트 연산자는 구조
체의 구성 요소인 멤버를 참조하기 위한 연산자이며 , 일반 형식은 다음과 같다.
| 형 식 |
| 구조체변수 , 구조체멤버명 ; |
| insu . number=2012 ; | younghi . number=2015 ; |
| insu . number="인수" ; | younghi . number="영희" ; |
| insu . number='m' ; | younghi . number='f' ; |
| insu . number=35 ; | younghi . number=22 ; |
| insu . number="서울" ; | younghi . number="인천" ; |
| insu . number="02-300-1234" ; | younghi . number="032-123-4567" ; |
여기서, 구조체 멤버 연산자는 구조체명과 멤버명을 서로 연결시켜 주는 의미를 가
진다. 이때 도트( . )는 연산자이므로 연산 우선 순위가 존재한다. 즉 증감 연산자(++ ,
-- )나 간접 연산자( * )보다 우선 순위가 높고 , 괄호 또는 대괄호( [ ] )와 같은 우선 순
위를 가진다. 그러므로 연산 우선 순위가 도트 연산자보다 낮은 연산자를 먼저 수행하
려면 반드시 괄호로 묶어야 한다.
구조체 변수도 단순 변수나 배열과 같이 기억 클래스( storage class )를 가진다. 구조
체 변수의 초기화는 배열과 같이 기억 클래스가 static 또는 extern인 경우에만 가능하
다. 구조체 변수의 초기값들은 다음과 같이 중괄호로 묶어서 나타낸다. 초기화를 하지
않은 경우에는 0(zero)으로 초기화된다.
| 형 식 |
| struct 구조체명 구조체변수명 = { 초기값1 , 초기값2 , ....., 초기값n } ; |
예를 들면 ,
struct score // 학생 성적을 정의하기 위한 구조체 score 정의
{
int hakbun ; // 학번
char name[ 20 ] ; // 이름
int internet ; // 인터넷 활용
int os ; // 운영 체제
int access ; // 액세스
int databass ; // 데이터베이스
int se ; // 소프트웨어 공학
} ;
static struct score student = { 201 , "홍길동" , 100 , 98 , 85 , 90 , 89 } ;
또는 다음과 같이 구조체를 정의하면서 구조체 변수의 선언과 동시에 구조체 변수를
초기화할 수 있다.
struct score
{
int hakbun ;
char name[ 20 ] ;
int internet ;
int os ;
int access ;
int databass ;
int se ;
} student = { 201 , "홍길동" , 100 , 98 , 85 , 90 , 89 } ;
|
||||||||||||||||||||||||||||||||||||||||||
구조체 배열( array of structure )은 일반 배열과 선언 형식이나 사용 방법이 같다. 단
지 배열 요소가 구조체로 되어 있다. 구조체 배열의 선언 형식은 다음과 같다.
| 형 식 |
| [ 기억클래스 ] struct 구조체명 배열명 [ 요소의 개수 ] ; |
예를 들어 ,
struct person
{
char name[ 20 ] ;
char sex ;
int age ;
} ;
와 같이 구조체가 정의되어 있다면 , 구조체 배열을 다음과 같이 선언할 수 있다.
struct person member[ 5 ] ;
또한 초기값을 고려하면 ,
static struct person member[ 5 ] = { { " Kwon " , 'M' , 22 } , { " Park " , 'F' , 20 } ,
{ " Choi " , 'F' , 22 } , { " Kim " , 'M' , 21 } , { " Jung " , 'M' , 20 } } ;
와 같이 선언할 수 있다. 여기서 배열 member는 5개의 배열 요소들로 이루어져 있으
며 , 각 배열 요소들은 person과 같은 구조체형을 갖는다. 이때 구조체 배열의 항목을
나타낼 경우에는 첨자가 배열의 요소에 붙는다. 즉 ,
| member[ 0 ] . name = " Kwon " ; | member[ 1 ] . name = " Park " ; |
| member[ 0 ] . sex = ' M '; | member[ 1 ] . sex = ' F ' ; |
| member[ 0 ] . age = 22 ; | member[ 1 ] . age = 20 ; |
| member[ 2 ] . name = " Choi " ; | member[ 3 ] . name = " Kim " ; |
| member[ 2 ] . sex = ' F ' ; | member[ 3 ] . sex = ' M ' ; |
| member[ 2 ] . age = 22 ; | member[ 3 ] . age = 21 ; |
| member[ 4 ] . name = " Jung " ; | |
| member[ 4 ] . sex = ' M ' ; | |
| member[ 4 ] . age =N20 | |
|
|||||||||||||||||||||
중첩된 구조체란 하나의 구조체 안에 구조체가 들어 있는 것을 의미한다. 예
를 들면 ,
struct Date // 구조체 Date 정의
{
int year ;
int month ;
int day ;
}
struct person // 구조체 person 정의
{
char name[ 20 ] ;
struct Date birthday ; // 구조체 변수 선언
char sex ;
int age ;
}customer ;
와 같이 선언할 수 있다. 여기서 구조체 person에는 다른 구조체 Date가 포함되어 있
다. 이와 같이 하나의 구조체가 다른 구조체를 포함하는 경우에 , 멤버( 항목 )의 참조는
도트 연산자( . )가 왼쪽에서 오른쪽으로 결합하여 차례로 멤버( 항목 )를 나열해 주면
된다. 예를 들면
customer . name ;
customer . birthday . year ;
customer . birthday . month ;
customer . birthday . day ;
와 같다.
|
구조체 변수를 선언할 때 포인터 형태로 선언할 수 있다. 실제 C 프로그램 작성 시
프로그램 내에서는 구조체 변수가 포인터 형태로 많이 사용된다. 그 이유는 다음과 같다.
① 배열 자체보다 배열에 대한 포인터로 처리하는 것이 더 쉬운 것과 같다 , 구조체
자체보다 구조체에 대한 포인터로 처리하는 것이 더 쉽다.
② 어떤 컴파일러에서는 구조체를 함수의 인수로 전달할 수 없도록 하고 있지만 , 구
조체에 대한 포인터는 함수의 인수로 사용할 수 있다.
③ 많은 데이터을이 구조체로 되어 있으며 , 이들 구조체의 구조체 멤버가 다른 구
조체를 가리키는 포인터 형태로 되어 있다.
구조체 포인터 변수 ( pointers to structures variables )의 선언 형식은 다음과 같다.
| 형 식 1 |
strcut [ 구조체명 ]
} * 구조체포인터변수명 ; |
| 형 식 2 |
| struct 구조체명 * 구조체포인터변수명 ; |
예를 들면 ,
struct Date
{
int year ;
int month ;
int day ;
} ;
struct Date today ; // 구조체 변수 today 선언
struct Date *date_ptr ; // 구조체 포인터 변수 date_ptr 선언
date_ptr = &today ;
여기서 , today는 구조체 변수이고 , date_ptr은 구조체 포인터 변수로 선언되어 있
다. 즉 date_ptr은 Date형의 구조체 변수인 today를 가리키는 포인터 변수로 선언된
것이다. 따라서 , date_ptr은 Date와 같은 구조체를 가리킨다. 이때 *date_ptr은 첫
번째 구조체가 되며 *( date_ptr + 1 )은 두 번째 구조체가 된다.
구조체 포인터 변수를 사용할 때 구조체 멤버를 참조하는 방법은 직접 참조와 간접
참조 두 가지 방법이 있다 즉 , 구조체 멤버를 참조하기 위해 도트 연산자를 이용하여
멤버를 직접 참조하는 방법과 , 포인터 변수를 이용하여 간접적으로 구조체 멤버를 참조
하는 방법이 있다.
구조체 포인터 연산자 ( -> : structure pointer operator )를 사용하여 멤버를 참조하
는 경우의 일반 형식은 다음과 같다.
| 형 식 1 |
| 구조체포인터변수 -> 멤버명 |
구조체 포인터 연산자는 구조체 변수가 포인터에 의해 지시되는 경우에 사용된다.
일반적인 변수와 동일하게 포인터 조작이 가능하다.
예를 들면 , 앞에서 정의한 구조체 Date에 있는 멤버를 참조하기 위해 구조체 포인터
변수 date_ptr을 이용하면 다음과 같이 나타낼 수 있다.
date_ptr -> year ;
date_ptr -> month ;
date_ptr -> day ;
| 형 식 2 |
| ( * 구조체포인터변수 ) . 멤버명 |
이때 도트 연산자( . )는 간접 연산자( * )보다 우선 순위가 높기 때문에 반드시 괄호( )
로 묶어 주어야 한다. 이것은 -> 연산자를 사용할 때와 같은 결과를 가진다. 예를 들면 ,
( *date_ptr ) . year ;
( *date_ptr ) . month ;
( *date_ptr ) . day ;
따라서 ,
date_ptr -> year == ( *date_ptr ) . year == today . year ;
date_ptr -> month == ( *date_ptr ) . month == today . month ;
date_ptr -> day == ( *date_ptr ) . day == today . day ;
가 성립된다.
다음 프로그램의 실행 결과를 나타내시오
} |
|
||||||||||||||||||||||||||||||||||||||||||||||||||
C 언어에서 구조체는 많은 제약이 있다. 즉 구조체 자체를 함수에 전달하거나 함수
로부터 전달받을 수 없다. 또한 오래된 컴파일러에서는 구조체의 전체 데이터를 한꺼번
에 다른 구조체의 값으로 대입할 수 없다.
구조체에 대하여 실행 가능한 연산자는 주소 연산자 ( & ) 뿐이다. 구조체 멤버는 하나
씩만 접근( access ) 할 수 있다. 그러므로 같은 형태의 구조체 변수들일지라도 구조체 변
수 자체를 다른 구조체 변수에 대입할 수 없으며 , 구조체 변수를 함수로 전달 ( 즉 함수
의 실인수로 사용 ) 하거나 함수의 결과값으로 리턴( return ) 할 수도 없다. 그러나 함수
에 구조체에 관한 정보를 전달할 수는 있다. 예를 들면 ,
struct Body
{
char name[ 20 ] ;
int height ;
float weight ;
} ;
static struct Body man = { "Hong Gil Dong " , 180 , 65.5 } ;
struct Body woman ;
에서 구조체 변수 man을 woman으로 전체를 복사하려면
woman . name = man . name ;
woman . height = man . height ;
woman . weight = man . weight ;
와 같이 항목별로 각각 처리해야 한다. 그러나 최근의 컴파일러에서는
woman = man ;
이 허용된다. 또한 어떤 컴파일러에서는 구조체 변수 자체를 함수의 실인수로 사용하는
것을 제한하고 있으나 , 항목이 하나의 값만을 가지는 변수라면 항목은 실인수로 사용이
가능하다.
일반적으로 구조체 전체를 실인수로 사용해야 하거나 , 함수의 결과값으로 사용해야
할 경우에는 포인터를 사용하면 된다. 그리고 프로그램에서 구조체 변수를 함수의 외부
에 정의한다면 , 모든 함수에서 그 구조체 항목을 사용할 수 있으므로 함수의 실인수를
사용하지 않고도 같은 효과를 얻을 수 있다.
또한 함수의 실인수로 구조체 배열을 사용할 수도 있으며 , 배열명은 배열의 시작 주
소를 나타내는 포인터 상수이므로 함수의 인수로 전달될 수 있다.
|
|||||||||||||||||||||||||||||||||||||||||||||||||
위 예제에서 함수 average( )의 실인수인 배열명 exam은 배열의 시작 주소를
가지는 포인터로서 i 의 값에 따라 다음과 같은 의미를 가진다.
exam = &exam[ 0 ]
exam + 1 == &exam[ 1 ]
exam + 2 == &exam[ 2 ]
exam + 3 == &exam[ 3 ]
exam + 4 == &exam[ 4 ]
프로그램을 작성하다 보면 어떤 변수가 i 와 0( zero )의 값 비트만을 필요로 하는 경
우가 있다. 이때 1바이트 ( byte ) 이상의 길이를 차지하는 변수로 선언하여 사용한다면
기억 장소를 낭비하는 것이다. 실제로는 1비트 ( bit )만 있으면 된다.
이와 같이 기억 장소를 효율적으로 사용하기 위하여 C 언어에서는 구조체 항목으로
비트 필드( bit field )를 사용할 수 있다. 비트 필드는 한 워드( word ) 안에 인접한 비트
들의 집합으로 이루어져 있으며 , 데이터형은 unsigned int 형으로만 선언할 수 있다. 그
러나 어떤 시스템에서는 int형도 가능하다 비트 필드로 이루어진 구조체 변수의 선언
형식은 다음과 같다.
| 형 식 |
|
예를 들면 ,
struct
{
unsigned x : 1 ;
unsigned y : 1 ;
unsigned z : 1 ;
} flag ;
에서 flag는 1비트 크기의 x , y, z를 비트 필드로 가지고 있는 구조체 변수이다. 비트
필드를 참조하는 방법은 일반 구조체 멤버를 참조하는 방법과 동일하다. 즉 다음과 같
이 구조체 변수명 . 멤버명 형식을 사용한다.
flag . x = 0 ;
flag . y = flag . z = 1 ;
if ( flag . x == 0 && flag . y == 0 )
비트 필드명을 생략하면 그 비트의 길이만큼 건너 뛴다. 그리고 , 이 부분은 필드명이
없으므로 참조할 수도 없다. 또한 비트 크기를 0( zero )으로 지정하면 , int형으로 경계선
정렬이 이루어져 다음의 비트 필드는 현재의 워드( word )에 남아 있는 비트들을 건너
뛰어 다음 워드( word )의 첫 번째 비트부터 시작하게 된다. 예를 들면
struct
{
unsigned a : 2 ;
unsigned b : 4 ;
unsigned : 0 ;
unsigned c : 1 ;
} flag ;
에서 flag는 다음과 같은 형태로 기억된다.
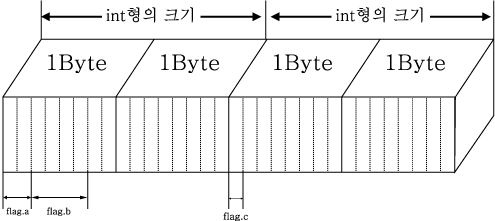
비트 필드는 다음과 같이 몇 가지 제약 사항이 있다.
① 비트 필드는 주소를 가지지 못하기 때문에 포인터를 사용할 수 없으며 , 주소 연
산자( & )도 사용할 수없다.
② 비트 필드는 배열로 선언할 수 없다.
③ 한 개의 비트 필드는 int형의 크기를 초과할 수 없으며 , 전체 비트 필드의 합도
int형의 크기를 초과할 수 없다. 또한 , 비트 필드는 int형의 경계에 맞아야 한다.
④ 비트 필드가 기계의 내부에 기억될 때 int형의 왼쪽 비트부터 오른쪽으로 기억될지
또는 오른쪽 비트에서 왼쪽으로 기억될지는 사용하는 시스템에 따라 달라진다.
|
| 비트7 | 비트0 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
공용체 ( Union )란 서로 다른 자료형을 가진 데이터들이 동일한 기억 장소를 공유하
며 기억되는 형태를 말한다. 그러나 , 어느 한 시점에서 오직 하나의 데이터형만이 그
기억 장소에 기억된다.
공용체의 정의 , 공용체 변수의 선언 및 공용체 변수의 멤버 ( 항목 )를 참조하는 방법
은 예약어 union을 사용한다는 것을 제외하고는 구조체와 동일하다. 공용체는 메모리
를 절약하기 위해 여러 가지 자료형의 데이터를 하나의 기억 장소에 기억시켜 놓고 필
요한 작업을 하고자 할 때 주로 사용된다.
공용체를 정의하는 일반 형식은 다음과 같다.
| 형 식 |
|
예를 들며 ,
union tag
{
int a ;
float b ;
char c ;
} ;
여기서 , 공용체 tag는 int , float , char의 3가지 데이터형 중에서 기억 장소를 가장 많
이 차지하는 float형의 길이 ( 4 byte )만큼의 기억 장소를 확보한 다음 , int , float , char
형의 데이터가 그 기억 장소를 공유하며 기억하게 된다. 그러므로 어느 한 시점에서 그
기억 장소에 기억되어 있는 데이터의 형과 값이 무엇인가를 판단하는 것은 전적으로
프로그래머의 책임이다.
공용체 변수를 선언하는 형식은 다음과 같다.
| 형 식 1 |
| union 공용체명 공용체변수1 [ , 공용체변수2 , ....... , 공용체변수n ] ; |
| 형 식 2 |
|
예를 들면 , 다음과 같이 공용체 변수를 선언할 수 있다.
|
공용체와 공용체 변수를 각각 선언한 경우 |
|
공용체와 공용체 변수를 동식에 선언한 경우 |
공용체의 초기화 방법은 구조체의 초기와 방법과 같다. 즉 , 중괄호 ( { , } )를 사용할
수 있다. 그러나 주의해야 할 점은 공요체의 초기화는 최초의 공용체 멤버( member )
값만 초기값을 배정할 수 있다는 것이다.
union u_test
{
int i ;
double d ;
} ;
union u_test data_value = { 12 } ;
여기서 , 공용체 , u_test는 int , double형의 2가지 데이터형 중에서 기억 장소를 가장
많이 차지하는 double형의 길이 ( 8 byte )만큼의 기억 장소를 확보한 다음 int , double
형의 데이터가 그 기억 장소를 서로 공유한다. 이때 초기값 12는 int형으로 i 의 값이
된다.
|
공용체 변수의 멤버를 참조하는 것은 구조체의 멤버를 참조하는 것과 같다. 그 형식
은 다음과 같다.
| 형 식 |
|
예를 들어 , 공용체 Data를 다음과 같이 선언한다고 하자 .
union Date
{
int num ;
double feet ;
char letter ;
} ;
union Data sample ;
위와 같이 공용체 변수 sample이 선언되었다면 8바이트로 구성된 기억 장소
sample에 대해 각 멤버를 다음과 같이 참조할 수 있다.
sample . num = 7 ;
sample . feet = 20.57 ;
sample . letter = 'a' ;
또한 공용체 변수는 배열이나 포인터 형태로도 선언될 수 있다. 예를 들면,
union Data number[ 5 ] ; // 공용체 배열을 선언하는 경우
union Data *ptr ; // 공용체 포인터 변수를 선언하는 경우
ptr = &number ;
위의 공용체 변수들은 다음과 같은 형태로 사용된다.
| number[ 1 ] . num = 20 ; | ptr -> num = 70 ; |
| number[ 1 ] . feet = 23.78 ; | ptr -> feet = 0.12 ; |
| number[ 1 ] . letter = 'A' ; | ptr -> letter = 'B' ; |
공용체는 구조체나 배열 속에 포함되어 나타날 수 있으며 , 반대로 공용체 내에 구조
체나 배열을 포함할 수도 있다. 이때 멤버를 참조하는 방법은 중첩된 구조체에서 멤버
를 참조하는 방법과 같다. 예를 들면 ,
struct
{
int number ;
char name[ 20 ] ;
union
{int age ;
float weight ;
char sex ;} data ;
} table[ 5 ] ;
에서 각 멤버는 다음과 같이 나타낼 수 있다.
table[ 0 ] . data . age = 21 ;
table[ 0 ] . data . weight = 12.345 ;
table[ 0 ] . data . sex = 'M' ;
table[ 0 ] . number = 1001 ;
table[ 0 ] . name = "Hong" ;
|
C 언어에서는 프로그래머가 기존의 데이터형 이름을 새로운 데이터형 이름으로 정의
할 수 있는 typedef이라는 명령이 있다. 새로운 형을 정의하는 typedef의 일반 형식
은 다음과 같다.
| 형 식 |
| typedef 기존의 데이터형 새로운 데이터형 ; |
여기서 , 기존의 데이터형은 int , float , char 등과 같은 시스템 데이터형이거나 프로그
매머가 typedef문으로 미리 선언한 새로운 데이터형일 수 있다. 예를 들어 , int형을
integer라는 이름으로 사용하고자 한다면 다음과 같이 선언하면 된다.
typedef int integer ;
이와 같이 선언하면 , integer를 int와 같이 정수형을 나타내는 새로운 데이터형으로
간주한다. 즉 , integer로 선언한 변수들은 int형으로 선언한 것과 같은 결과를 얻게
된다.
예를 들면 ,
integer a , b , c ;
와
int a , b , c ;
는 동일하다. 즉 변수 a , b , c는 모두 정수형 ( int )으로 취급된다.
일반적으로 기존의 데이터형과 구분하기 위해 새로운 데이터형은 대문자를 많이 사
용한다. 예를 들면
| typedef | int | INTEGER |
| typedef | float | REAL |
| typedef | REAL | SILSU |
| INTEGER i , j , k ; | ==> int i , j , k 와 같다. |
| REAL x , y[ 10 ] , *ptr ; | ==> float x , y[ 10 ] , *ptr과 같다. |
| SILSU z ; | ==> float z 와 같다. |
또한,
typedef char *string ;
에서 새로운 데이터형 string은 char * , 즉 문자형 포인터 변수를 나타낸다. 따라서 ,
string name , address ;
는
char *name , *address ;
와 같다. 또한
typedef char string[ 10 ] ;
string letters , text ;
는
char letters[ 10 ] , text[ 10 ] ;
와 동일하다. typedef문은 구조체에서도 사용할 수 있다, 예를 들면 ,
typedef struct
{
float a ;
float b ;
} complex ;
complex value ;
와 같이 complex는 다른 구조체 변수를 선언하는 데 사용할 수 있다. 이것은
struct
{
float a ;
float b ;
} value ;
를 의미한다.
C 언어에서 typedef문과 #define문은 데이터형을 정의하는 관점에서 볼 때 비슷한
점들을 많이 가지고 있지만, 다음과 같은 차이가 있다.
① typedef는 #define과 달리 데이터형을 정의하는 데에만 사용된다.
② typedef는 컴파일러에 의해 실행되고 #define은 선행처리기 ( perprocessor )에
의해 실행된다.
③ 데이터형의 정의는 #define도 가능하지만 typedef 보다 융통성이 많다.
C 언어에서 기존의 데이터형을 typedef로 다시 선언하여 사용하는 이유는 다음과
같다. typedef문은 데이터형을 보다 편리하고, 쉽게 인식할 수 있도록 해 준다. 그리
고 C 언어의 데이터형은 컴퓨터에 따라 기억되는 크기가 다를 수 있다. 예를 들어 ,
프로그램이 16비트( 2byte ) 길이의 정수형 변수를 필요로 한다면 어떤 시스템에서는
int로 선언하면 된다. 그러나 다른 시스템에서는 int가 32비트의 길이를 가지므로 이
때는 short형으로 선언해 주어야 한다. 그러므로 변수를 선언할 때 int로 선언하지
않고
typedef int TWOBYTE ;
와 같이 선언한 다음 프로그램에서 정수형 변수를 TWOBYTE로 선언하여 사용하면
된다.
이러한 경우 int가 32비트인 컴퓨터에서 프로그램을 실행하려면 ,
typedef int TWOBYTE ;
를
typedef short TWOBYTE ;
로 프로그램을 수정해 주면 된다. 따라서 typedef문으로 나타내면 프로그램의 이식성
을 높일 수 있다.
|
열거형 데이터는 데이터가 가질 수 있는 모든 값들을 나열함으로써 정의되는 데이터
들의 집합 구조를 의미한다. 이것은 예약어 enum을 이용하여 새로운 데이터형과 그
데이터형이 사용할 수 있는 상수들을 정의한다 . 열거형 데이터의 정의와 열거형 변수의
선언 형식은 다음과 같다.
| 형 식 1 ( 열거형 정의 ) |
| enum 열거형이름 { 열거형 상수 리스트 } ; |
| 형 식 2 ( 열거형 변수의 선언 ) |
| enum 열거형이름 열거형변수1 [ , 열거형변수2 , ..... , 열거형변수n ] ; 또는 enum 열거형이름 { 열거형 상수 리스트 } 열거형변수1 [ , 열거형변수2 , ..... , 열거형변수n ] ; |
|